Migraciones ETL de Big Data
Ejecuté múltiples proyectos de migración ETL de Oracle a AWS Glue, con fuerte énfasis en la recolección detallada de requisitos y planificación integral
Tecnologías Utilizadas
Este artículo también está disponible en inglés
🇺🇸 English
Durante mis dos años en Xaldigital, tuve la oportunidad de participar en varios proyectos desafiantes enfocados en la migración de datos y la automatización en la nube. Estos proyectos abarcaron desde la gestión de leads hasta la integración de encuestas de clientes y empleados, así como la creación de un registro maestro de clientes. Aquí tienes un resumen de estos proyectos:
-
Uno de los primeros proyectos en los que trabajé fue la automatización del procesamiento de leads.
-
Esto implicó migrar un proyecto existente de SAS Enterprise Guide 7.1 a una infraestructura sin servidor en AWS.
-
El flujo de trabajo incluía:
-
Descargar archivos CSV de un servidor SFTP.
-
Limpieza y transformación de datos.
-
Generación de tablas delta.
-
Actualización de la base de datos maestra.
-
Además, implementamos despliegue continuo y orquestación de procesos utilizando AWS Step Functions.
-
En otro proyecto, automatizamos el procesamiento de los resultados de encuestas de clientes recibidos en formato CSV de Medallia.
-
Utilizamos EventBridge para activar el flujo de Step Functions, AWS Glue para extraer la información a Amazon S3, y luego lo integramos en Redshift.
-
Al final del proceso, se envió una notificación a través de SNS.
-
Un proyecto similar al anterior, pero en este caso, procesamos los resultados de las encuestas de empleados.
-
La arquitectura y las tecnologías utilizadas fueron muy similares, incluyendo EventBridge, Step Functions, AWS Glue y Redshift.
-
Uno de los proyectos más desafiantes fue la creación de un registro maestro de clientes.
-
Aquí, integramos información de diferentes sistemas internos (como Rackspace y Aeroméxico) con la nube de AWS, manteniendo la continuidad de los flujos de trabajo existentes.
-
Utilizamos AWS Glue y Step Functions para orquestar todo el proceso.
-
Finalmente, trabajé en un proyecto donde se subieron archivos CSV generados por SAS en un servidor interno a la nube de AWS para su procesamiento.
-
También utilizamos AWS Glue y Step Functions, junto con Lambda para la integración con SAS.
Estos proyectos me permitieron desarrollar habilidades clave en automatización de flujos de datos, integración de sistemas, despliegue continuo y orquestación de procesos en la nube. Fue un desafío constante, pero increíblemente gratificante optimizar y escalar estos flujos de trabajo.
Si deseas aprender más sobre cada uno de estos proyectos, no dudes en hacer clic en los enlaces correspondientes.
Publicaciones Relacionadas
Explora más artículos sobre temas y tecnologías similares.

Flujo de datos escalable
Reduje significativamente los gastos de infraestructura en AWS

Arquitectura Black Belt
Demostración de conocimiento avanzado en arquitectura de software
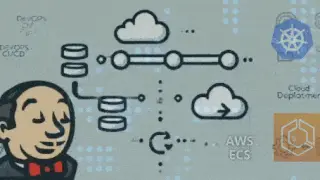
Orquestación de contenedores Backend CI/CD
Usando ECS que es ❝similar a kubernetes❞ desplegado automáticamente vía Jenkins, desplegué un contenedor